摘要:InnoDB表空间文件.ibd文件内部存储单元是页,初始大小为 96K,而InnoDB默认页大小为 16K。当然页大小也可以通过 innodb_page_size 配置为 4K, 8K…64K 等。
如果用二进制打开,以16K划分一页。在ibd文件中,0-16KB偏移量即为0号数据页,16KB-32KB的为1号数据页,以此类推。
表空间物理结构-页、区、段
磁盘最小单位是512字节,操作系统是4KB,mysql里最小的是page(页面)有16K。
ibd就是放索引树的,但总不能一个树就摊在一个txt文档里,所以必须还要有一种文件组织结构。所有的数据都放在page里,用一种规则来把N个page连一起,让它们形成一些关联,才能便于查询,要先找到page,再找到page内的数据。
B+树是离不开页面page
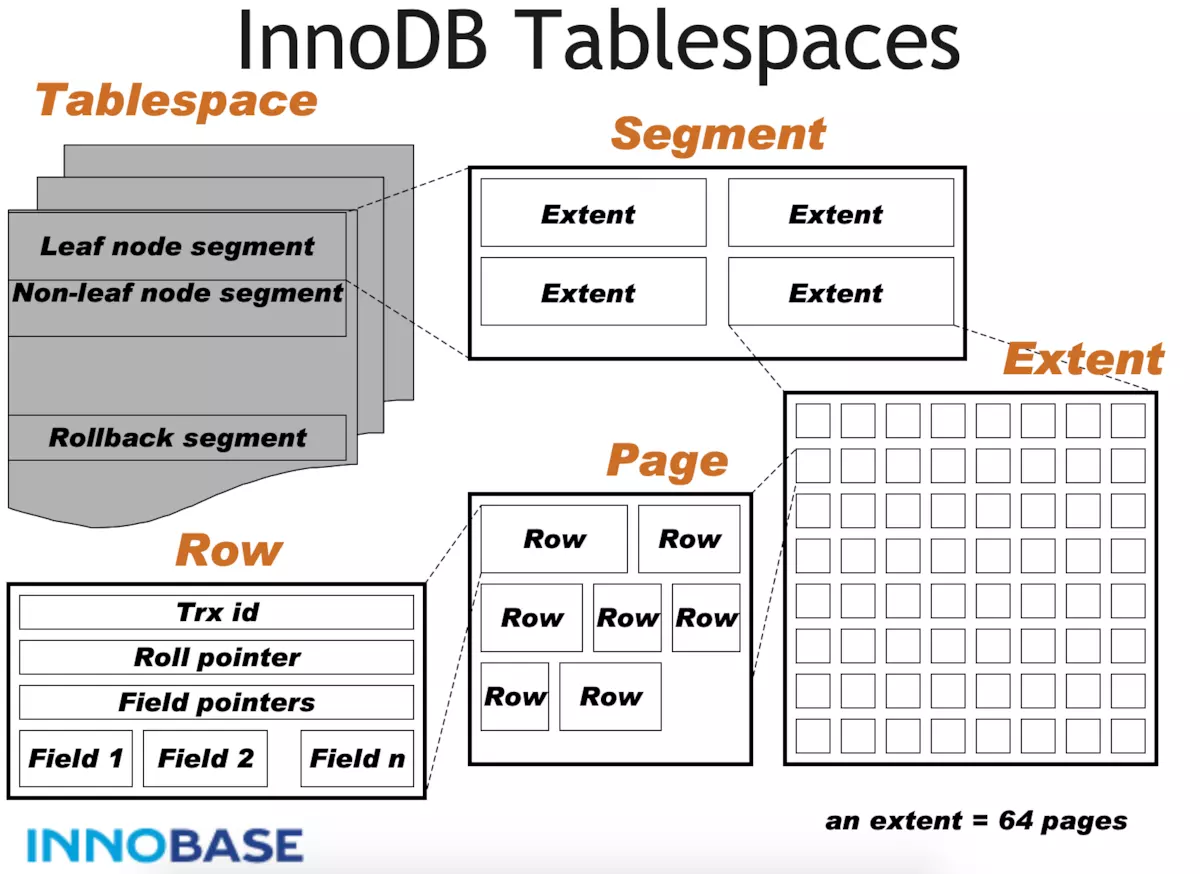
段(segment)
段是表空间文件中的主要组织结构,它是一个逻辑概念,用来管理物理文件,是构成索引、表、回滚段的基本元素。
表空间是由各个段组成的,常见的段有数据段、索引段、回滚段等。
InnoDB存储引擎表是索引组织的(index organized),因此数据即索引,索引即数据。那么数据段即为B+树的页节点(上图的leaf node segment),索引段即为B+树的非索引节点(上图的non-leaf node segment)。
创建一个索引(B+树)时会同时创建两个段,分别是内节点段和叶子段,内节点段用来管理(存储)B+树非叶子(页面)的数据(分裂、增长、删除等),叶子段用来管理(存储)B+树叶子节点的数据,负责行数据的相关动作;
也就是说,在索引数据量一直增长的过程中,所有新的存储空间的申请,都是从“段”这个概念中申请的。一个段包含256个区(256M大小)。
区/簇(extents)
段是个逻辑概念,innodb引入了簇的概念,在代码中被称为extent;
簇是由64个连续的页组成的,每个页大小为16KB,即每个簇的大小为1MB硬盘空间。即默认大小为 1MB (64*16K)。
簇是构成段的基本元素,一个段由若干个簇构成。一个簇是物理上连续分配的一个段空间,每一个段至少会有一个簇,在创建一个段时会创建一个默认的簇。
如果存储数据时,即往段里写入数据,就是往簇里写数据,簇是硬盘空间,当一个簇已经不足以放下更多的数据,此时需要从这个段中分配一个新的簇来存放新的数据,等于又多了一块64*16K的连续硬盘空间。
一个段所管理的空间大小是无限的,可一直扩展下去,但是扩展的最小单位就是簇。注意,每个簇是一块连续的硬盘空间,但多个簇之间可不是连续的。
同样,两个段之间,在硬盘上也没有什么关系。
页(page)
页存储单元
磁盘扇区、文件系统、InnoDB 存储引擎都有各自的最小存储单元。存储数据的最小单位。
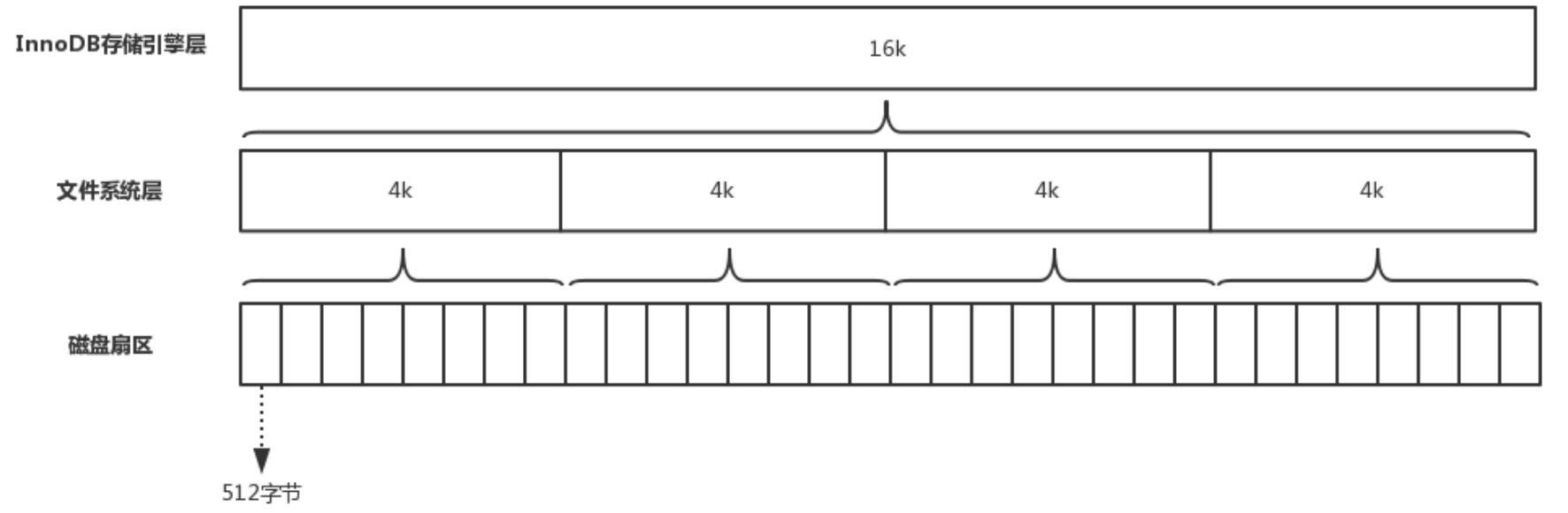
磁盘扇区存储单元-扇区-512字节
在计算机中磁盘存储数据最小单元是扇区,一个扇区的大小是 512 字节文件系统存储单元-块-4k
文件系统(例如 XFS/EXT4)他的最小单元是块,一个块的大小是 4K。
文件系统中一个文件大小只有 1 个字节,但不得不占磁盘上 4KB 的空间。[0k不占空间]
InnoDB存储单元-页-16k
InnoDB 存储引擎也有自己的最小储存单元——页(Page),一个页的大小是 16K。
InnoDB 的所有数据文件(后缀为 ibd 的文件),他的大小始终都是 16384(16K)的整数倍。
1 | $ ll |grep ibd |
InnoDB有页(page)的概念,可以理解为簇的细化。页是InnoDB磁盘管理的最小单位。
页结构
所有页的结构都是一样的,分为文件头(前38字节),页数据和文件尾(后8字节)。页数据根据页的类型不同而不一样。
页的头尾除了一些元信息外,还有Checksum校验值,这些校验值在写入磁盘前计算得到,当从磁盘中读取时,重新计算校验值并与数据页中存储的对比,如果发现不同,则会导致 MySQL 崩溃。
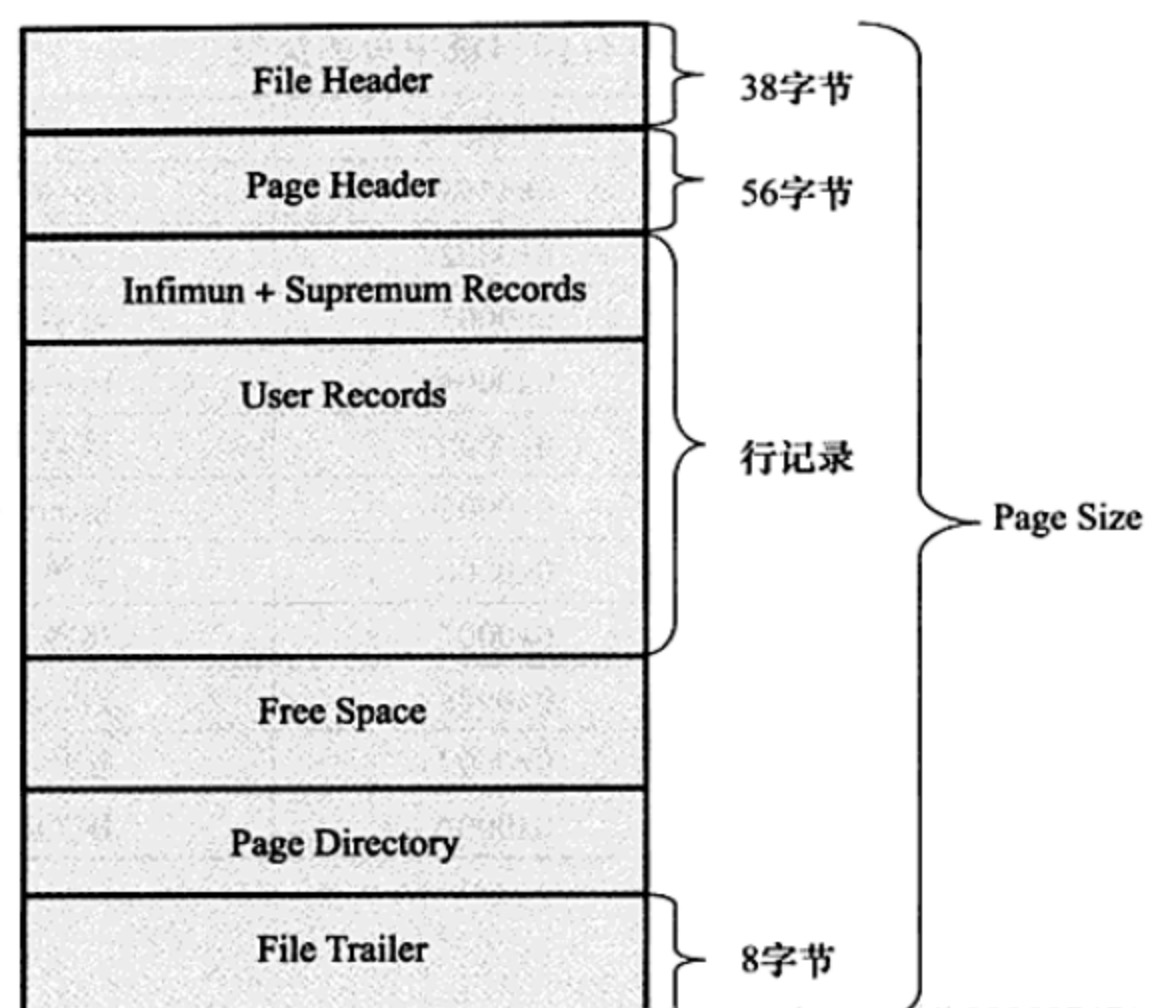
File Header 记录页的一些头信息,共占用38字节,组成部分如:
1 | 名称 大小(Bytes) 描述 |
页类型【innodb存储引擎中】
1 | 名称 大小(Bytes) 描述 |
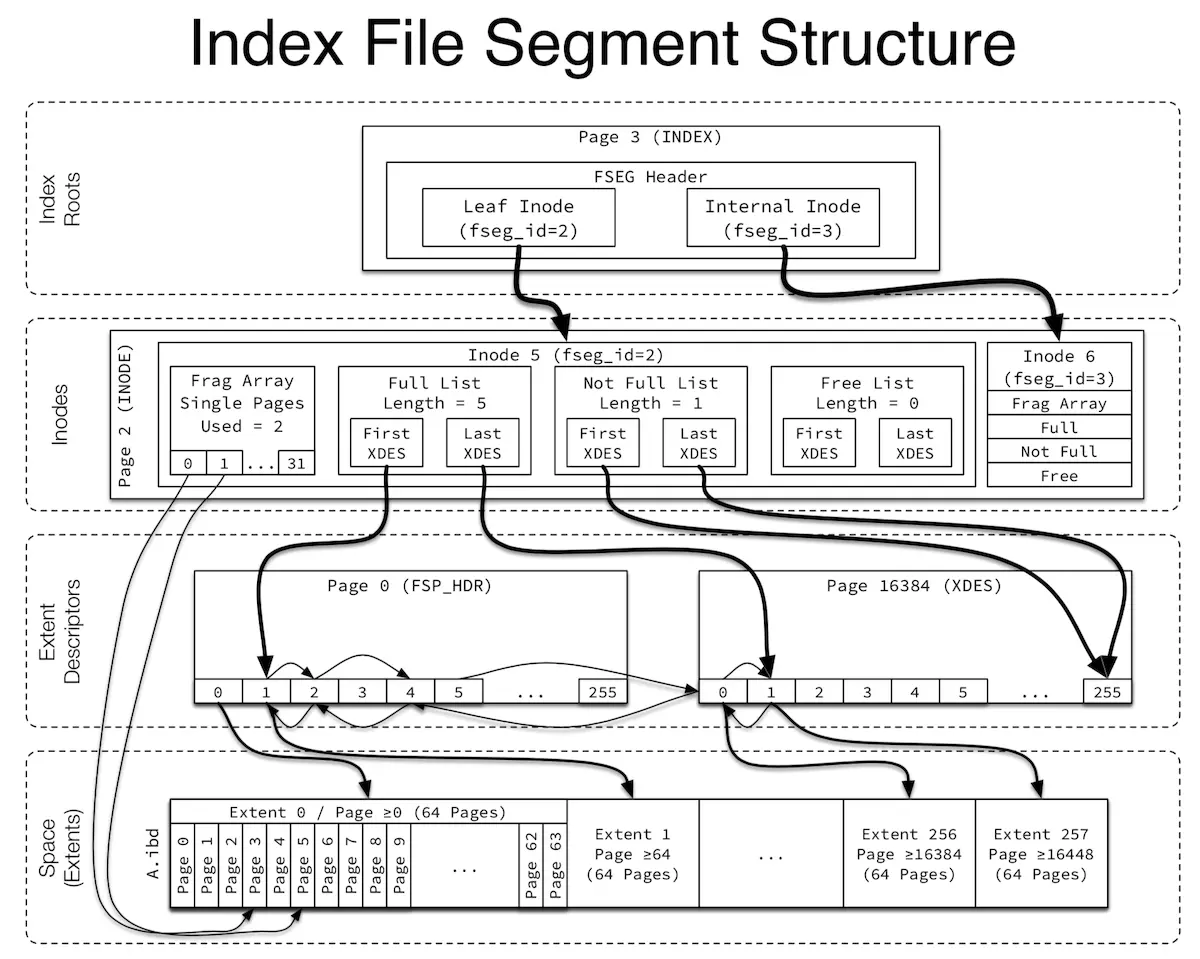
FIL_PAGE_INODE:用于记录文件段(FSEG)的信息,每页有85个INODE entry,每个INODE entry占用192字节,用于描述一个文件段。每个INODE entry包括文件段ID、属于该段的区的信息以及碎片页数组。区信息包括 FREE(完全空闲的区), NOT_FULL(至少使用了一个页的区), FULL(没空闲页的区)三种类型的区的List Base Node(包含链表长度和头尾页号和偏移的结构体)。碎片页数组则是不同于分配整个区的单独分配的32个页。
FIL_PAGE_TYPE_FSP_HDR 页:用于存储区的元信息。
ibd文件的第一页 FSP_HDR 页通常就用于存储区的元信息,里面的256个 XDES(extent descriptors) 项存储了256个区的元信息,包括区的使用情况和区里面页的使用情况。更多 参看 附表
Page Header:记录数据页的状态信息,共占56个字节,组成部分如图:
1 | 名称 大小(Bytes) 描述 |
infimum和supermum record
- 每个数据页中都有两个虚拟的行记录,用来限定记录(User Record)的边界(Infimum为下界,Supremum为上界)
- Infimum和Supremum在页被创建是自动创建,不会被删除
- 在Compact和Redundant行记录格式下,Infimum和Supremum占用的字节数是不一样的
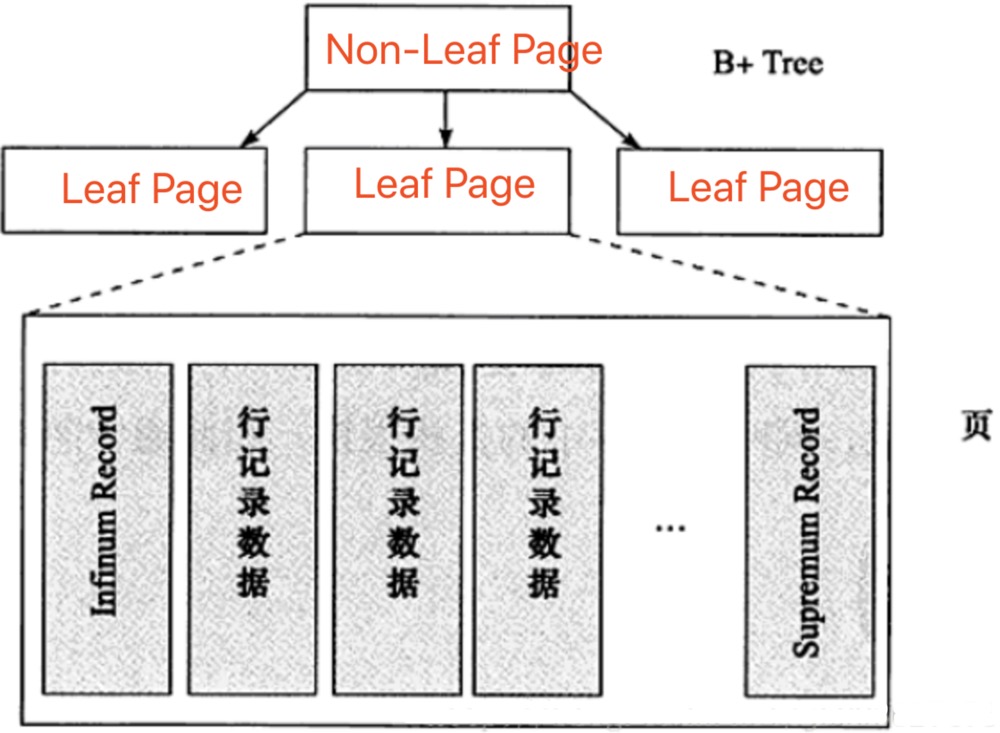
- 5.1后有Compact(默认)和Redundant两种格式
- Compact行记录格式
设计目标为高效存放数据,行数据越多,性能越高。1
变长字段长度列表 | NULL标志位 | 记录头信息 | 列1数据 | 列2数据 | …… |
- 变长字段长度列表,按照列的顺序逆序放置。列长度小于255字节,用1字节表示,大于255字节,则用2个字节表示
- NULL标志位,一个字节,表示对应列为NULL
- 记录头信息,5个字节,含义见下表
- 下面即为数据列,NULL不占用存储空间
- 每行除了用户定义的列,还有两个隐藏列,事务ID列(6字节)和回滚指针列(7字节),若没有定义主键,每行还会有一个6字节的RowID列
Compact行记录格式 1
2
3
4
5
6
7
8
9名称 大小(bit) 描述
() 1 未知
() 1 未知
deleted_flag 1 该行是否被删除
min_rec_flag 1 为1,如果该记录是预先被定义为最小的记录
n_owned 4 该记录拥有的记录数
heap_no 13 索引堆中该条记录的排序记录
record_type 3 记录类型 000=普通 001=B+树节点指针 010-Infimum 011=Supremum 1xx=保留
next_recorder 16 页中下一条记录的相对位置
- Redundant行记录格式
- Compact行记录格式
1 | 字段长度偏移列表 | 记录头信息 | 列1数据 | 列2数据 | …… | |
- 字段长度偏移列表,按照列的顺序逆序放置。列长度小于255字节,用1字节表示,大于255字节,则用2个字节表示
- 记录头信息,固定占用6个字节,含义见下表。n_fields、1byte_offs_flag两个值值得注意
- 数据列,varchar的NULL值不占用存储空间,但是char值需要占用空间
1 | 名称 大小(bit) 描述 |
User Records
- 存储实际插入的行记录
- 在Page Header中PAGE_HEAP_TOP、PAGE_N_HEAP的HEAP,实际上指的是Unordered User Record List
- InnoDB不想每次都依据B+Tree键的顺序来插入新行,因为这可能需要移动大量的数据
- 因此InnoDB插入新行时,通常是插入到当前行的后面(Free Space的顶部)或者是已删除行留下来的空间
- 为了保证访问B+Tree记录的顺序性,在每个记录中都有一个指向下一条记录的指针,以此构成了一条单向有序链表
Free Space
- 空闲空间,数据结构是链表,在一个记录被删除后,该空间会被加入到空闲链表中
Page Directory
- 存放着行记录(User Record)的相对位置(不是偏移量)
- 这里的行记录指针称为Slot或Directory Slot,每个Slot占用2Byte
- 并不是每一个行记录都有一个Slot,一个Slot中可能包含多条行记录,通过行记录中n_owned字段标识
- Infimum的n_owned总是1,Supremum的n_owned为[1,8],User Record的n_owned为[4,8]
- Slot是按照索引键值的顺序进行逆序存放(Infimum是下界,Supremum是上界),可以利用二分查找快速地定位一个粗略的结果,然后再通过next_record进行精确查找
- B+Tree索引本身并不能直接找到具体的一行记录,只能找到该行记录所在的页
- 数据库把页载入到内存中,然后通过Page Directory再进行二分查找
- 二分查找时间复杂度很低,又在内存中进行查找,这部分的时间基本开销可以忽略
File Trailer
- 总共8 Bytes,为了检测页是否已经完整地写入磁盘
- 变量innodb_checksums,InnoDB从磁盘读取一个页时是否会检测页的完整性
- 变量innodb_checksum_algorithm,检验和算法
1
2称 大小(Bytes) 描述
FIL_PAGE_END_LSN 8 前4Bytes与File Header中的FIL_PAGE_SPACE一致,后4Bytes与File Header中的FIL_PAGE_LSN的后4Bytes一致1
2
3
4
5
6
7
8
9
10
11
12
13
14mysql> SHOW VARIABLES LIKE 'innodb_checksums';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| innodb_checksums | ON |
+------------------+-------+
row in set (0.01 sec)
mysql> SHOW VARIABLES LIKE 'innodb_checksum_algorithm';
+---------------------------+-------+
| Variable_name | Value |
+---------------------------+-------+
| innodb_checksum_algorithm | crc32 |
+---------------------------+-------+
row in set (0.00 sec)
小结
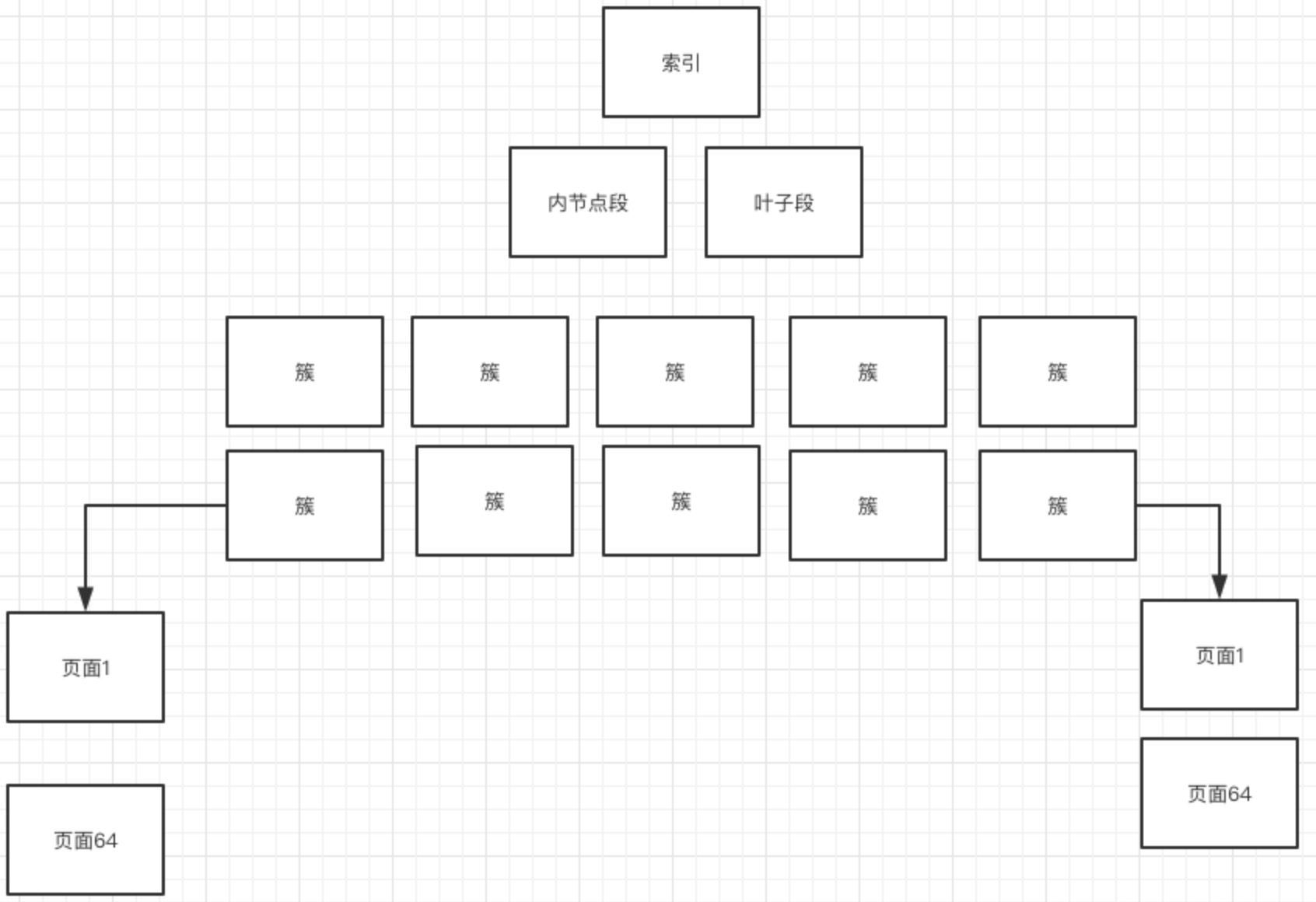
每个簇里有64个页面,都会进行编号,页面就是最小的存储单元了。在逻辑上(页面号都是从小到大连续的)及物理上都是连续的。
在向表中插入数据时,如果一个页面已经被写完,系统会从当前簇中分配一个新的空闲页面处理使用,如果当前簇中的64个页面都被分配完,系统会从当前页面所在段中分配一个新的簇,然后再从这个簇中分配一个新的页面来使用;
- 一个页面16K,放主键如int型能放几千,放一行数据,如1K一行,能放十几行。
- 这里需要注意,一行数据尽量不要过大,一旦跨page,就会对性能产生影响。本来一个page就能查出来,结果每次要查2个page,那性能就丢了一倍。
1 | Pages, Extents, Segments, and Tablespaces |
表空间ibd与页关系
一个表,占用一个表空间,创建一个表空间时,至少有一个文件(0号文件),这个文件的第一个页面page,page_no=0,这个page中存储了这个表空间中,所有段、簇、页管理的入口。
InnoDB表空间文件.ibd文件内部存储单元是页,初始大小为 96K,而InnoDB默认页大小为 16K。当然页大小也可以通过 innodb_page_size 配置为 4K, 8K…64K 等。
如果用二进制打开,以16K划分一页。在ibd文件中,0-16KB偏移量即为0号数据页,16KB-32KB的为1号数据页,以此类推。
ibd文件存储结构【页】
- 图形

更为抽象一点的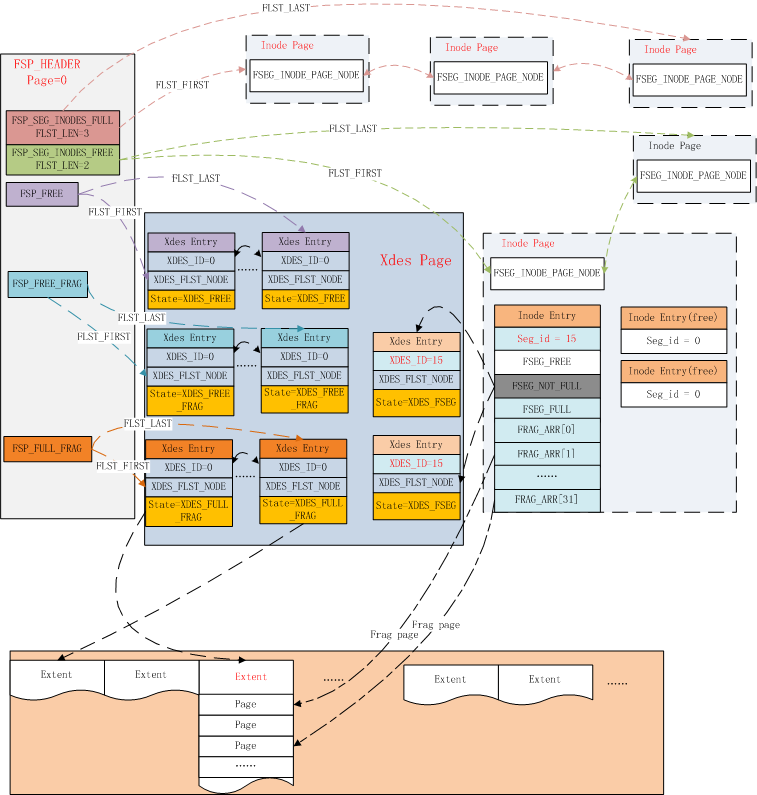
- sql查询
可以在 innodb_sys_tables 表中查到表t的表空间ID为 36,然后可以在 innodb_buffer_page查到所有页信息,一共4个页。
分别是 FSP_HDR, IBUF_BITMAP, INODE, INDEX。1
2
3SELECT * FROM INFORMATION_SCHEMA.INNODB_SYS_TABLES WHERE NAME='test_innodb/table15w'
select * from information_schema.innodb_buffer_page where SPACE=36; - 实际文件结构:
- 第0页是 FSP_HDR 页,主要用于跟踪表空间,空闲链表、碎片页以及区等信息。
- 第1页是 IBUF_BITMAP 页,保存Change Buffer的位图。
- 第2页是 INODE 页,用于存储区和单独分配的碎片页信息,包括FULL、FREE、NOT_FULL 等页列表的基础结点信息(基础结点信息记录了列表的起始和结束页号和偏移等),这些结点指向的是 FSP_HDR 页中的项,用于记录页的使用情况,它们之间关系如下图所示。
- 第3页开始是索引页 INDEX(B-tree node),从 0xc000(每页16K) 开始,后面还有些分配的未使用的页。
表空间文件ibd-页类型-实操说明
FSP_HDR PAGE【File Space Header Page】
数据文件.ibd的第一个Page类型为FIL_PAGE_TYPE_FSP_HDR,在创建一个新的表空间时进行初始化(fsp_header_init),
该page同时用于跟踪随后的256个Extent(约256MB文件大小)的空间管理,所以每隔256MB就要创建一个类似的数据页,类型为FIL_PAGE_TYPE_XDES ,XDES Page除了文件头部外,
其他都和FSP_HDR页具有相同的数据结构,可以称之为Extent描述页,每个Extent占用40个字节,一个XDES Page最多描述256个Extent。
FSP_HDR页的头部使用FSP_HEADER_SIZE个字节来记录文件的相关信息,具体的包括:
1 | Macro bytes Desc |
第一页的 前38字节
1 | hexdump -C -n 38 table5hang.ibd |
通过 :File Header 记录页的一些头信息 参看
1 | 名称 大小(Bytes) 描述 |
IBUF_BITMAP Page
第2个page类型为FIL_PAGE_IBUF_BITMAP,主要用于跟踪随后的每个page的change buffer信息,使用4个bit来描述每个page的change buffer信息。
1 | Macro bits Desc |
由于bitmap page的空间有限,同样每隔256个Extent Page之后,也会在XDES PAGE之后创建一个ibuf bitmap page。
offsets:1610241=16384
1 | hexdump -C -s 16384 -n 38 table5hang.ibd |
前 38也是 File Header
00 05 : FIL_PAGE_IBUF_BITMAP 0x0005 插入缓冲位图页(Insert Buffer Bitmap)。用于记录 change buffer的使用情况。
FIL_PAGE_INODE
数据文件的第3个page的类型为FIL_PAGE_INODE,用于管理数据文件中的segement,每个索引占用2个segment,分别用于管理叶子节点和非叶子节点。
每个inode页可以存储FSP_SEG_INODES_PER_PAGE(默认为85)个记录。
1 | Macro bits Desc |
每个Inode Entry的结构如下表所示:
1 | Macro bits Desc |
offsets:1610242=32768
1 | hexdump -C -s 32768 -n 38 table5hang.ibd |
前 38也是 File Header
00 03 : 索引节点
1 | Macro bits Desc |
每个Inode Entry的结构如下表所示:
1 | Macro bits Desc |
Index 索引页
需要跳过3页面,即 49152,索引页 结构也符合基础页结构。

同上述步骤类似
FIL Header(38字节): 记录文件头信息。
offsets:1610243=49152
1 | hexdump -C -s 49152 -n 38 table5hang.ibd |
前4字节 3b 03 ff eb 是 checksum,接着4个 00 00 00 03 是页偏移值 3,即这是第2+1页。【数组下标方式,这是真实的第四页】
接着 4 字节是上一页偏移值,ff ff ff ff 第一个数据页 无上一页,接着 4 字节是下一页偏移值 ff ff ff ff 无下一页。
然后 8 字节 00 00 00 00 80 eb af c9 是日志序列号 LSN。
随后的 2 字节 45 bf 是页类型,代表是 INDEX 页。
接着 8 字节 00 00 00 00 00 00 00 00 表示被更新到的LSN,在 File-Per-Table 表空间中都是0。
然后 4 字节 00 00 00 2c 表示该数据页属于的表t的表空间ID是 0x2c(44)。 与上文sql 查询一致
1 | SELECT * FROM INFORMATION_SCHEMA.INNODB_SYS_TABLES WHERE NAME='test_innodb/table5hang' |
PageHeader-INDEX Header(56字节): 记录的是 INDEX 页的状态信息
offsets:1610243+38=49190
1 | hexdump -C -s 49190 -n 56 table5hang.ibd |
1 | 名称 大小(Bytes) 描述 |
PAGE_INDEX_ID = 3c =3*16+12=60 索引ID可以在information_schema.INNODB_SYS_INDEXES 中查询
1 | select * from information_schema.INNODB_SYS_INDEXES |
1 | index_id name table_id type n_fields page_no space |
PAGE_BTR_SEG_LEAF和PAGE_BTR_SEG_TOP INDEX页中的根结点才有的,非根结点的为0。
前10字节 00 00 00 2c 00 00 00 02 00 f2 是叶子结点所在段的segment header,分别记录了叶子结点的表空间ID 0x24,INODE页的页号 2 和 INODE项偏移 0xf2。
后10字节 00 00 00 2c 00 00 00 02 00 32 是非叶子结点所在段的segment header,偏移分别是0xf2 和 0x32,即INODE页的前2个Entry,文件段ID分别是1和2。
FSEG Header中存储了该 INDEX 页的INODE项,INODE项里面则记录了该页存储所在的文件段以及文件段页的使用情况。对于 File-Per-Table情况下,每个单独的表空间文件的 FSP_HDR 页负责管理页使用情况。
System Records(26字节)-infimum和supermum record
offset:1610243+38+56 = 49246
1 | hexdump -C -s 49246 -n 60 table5hang.ibd |
1 | 01 00 02 00 1c 69 6e 66 69 6d 75 6d 00 |.....infimum....| |
每个 INDEX 页都有两条虚拟记录 infimum 和 supremum,用于限定记录的边界,各占 13 个字节。
其中记录头的5个字节分别标识了拥有记录的数目和类型(拥有记录数目是即后面页目录部分的owned值,当前页目录只有两个槽,infimum拥有记录数只有它自己为1,
而supremum拥有我们插入的5条记录和它自己,故为6)、下一条记录的偏移 0x1c=28 向后【当前位置】偏移 28个,即位置是 0xC062+0x1c=0xc07e 的后一个 0xco7f,这就是我们实际数据记录开始位置。
后面8个字节为 infimum + 空值,supremum类似,只是它下一条记录偏移为0。
User Records
offset:1610243+38+56 +26 = 49272
1 | hexdump -C -s 49272 -n 1000 table5hang.ibd |
查看 行记录格式
1 | SHOW TABLE STATUS from test_innodb like 'table5hang' |
1 | 接下来是插入的记录。Compact 【变长字段长度列表 小于255 1字节,大于 255 2】 |
1 | 第一行 |
FIL Tail (8字节)
offset:1610244 - 8 = 65528
1 | hexdump -C -s 65528 -n 8 table5hang.ibd |
其中 bd 11 4b e6 为 checknum,跟 FIL Header的checksum一样。【没有匹配上,需要继续查看资料】
后4字节80 eb af c9 与 FIL Header的LSN的后4个字节一致。
通过 innodb_ruby 工具来分析表空间文件
mac安装
1 | brew install ruby |
查看具体数据
1 | innodb_space -s /Users/lihongxu6/docker/mymysql56/data/ibdata1 -T test_innodb/table5hang -p 3 page-records |
其他-XDES页
簇或者分区(extent)是段的组成元素,在文件头使用FLAG描述了创建表信息,除此之外其他部分的数据结构和XDES PAGE都是相同的,
使用连续数组的方式,每个XDES PAGE最多存储256个XDES Entry,每个Entry占用40个字节,描述64个Page(即一个Extent)。格式如下:
1 | Macro bytes Desc |
XDES_STATE表示该Extent的四种不同状态:
1 | Macro Desc |
通过XDES_STATE信息,我们只需要一个FLIST_NODE节点就可以维护每个Extent的信息,是处于全局表空间的链表上,还是某个btree segment的链表上。
文件维护
从上文我们可以看到,InnoDB通过Inode Entry来管理每个Segment占用的数据页,每个segment可以看做一个文件页维护单元。Inode Entry所在的inode page有可能存放满,因此又通过头Page维护了Inode Page链表。
在ibd的第一个Page中还维护了表空间内Extent的FREE、FREE_FRAG、FULL_FRAG三个Extent链表;而每个Inode Entry也维护了对应的FREE、NOT_FULL、FULL三个Extent链表。这些链表之间存在着转换关系,以高效的利用数据文件空间。
注意区别:表空间中的链表管理的是整个表空间中所有的簇,包括满簇、半满簇及空闲簇,而段的iNode信息中管理的是属于自己段中的满簇、半满簇及空闲簇。
当创建一个新的索引时,实际上构建一个新的btree(btr_create),先为非叶子节点Segment分配一个inode entry,再创建root page,并将该segment的位置记录到root page中,然后再分配leaf segment的Inode entry,并记录到root page中。当删除某个索引后,该索引占用的空间需要能被重新利用起来。
创建一个segment:
函数入口:fseg_create_general。
根据空间id得到表空间头信息。
从得到的表空间头信息分配Inode:具体实现为读取文件头Page并加锁(fsp_get_space_header),然后开始为其分配Inode Entry(fsp_alloc_seg_inode)。
为了管理Inode Page,在文件头存储了两个Inode Page链表,一个链接已经用满的inode page,一个链接尚未用满的inode page。如果当前Inode Page的空间使用完了,
就需要再分配一个inode page,并加入到FSP_SEG_INODES_FREE链表上(fsp_alloc_seg_inode_page)。对于独立表空间,通常一个inode page就足够了。
具体查找inode Page过程:首先判断FSP_SEG_INODES_FREE链表是否还有空闲页面,如果有,则从页面的数据存储位置开始扫描,没找一个Inode,先判断是否空闲(空闲表示其不归属任何segment,即FSEG_ID置为0)。
找到则返回。找到这个且这个Inode为这个页最后一个Inode.则该inode page中的记录用满了,就从FSP_SEG_INODES_FREE链表上转移到FSP_SEG_INODES_FULL链表。
如果FSP_SEG_INODES_FREE没有空闲的Inode页面,则重新分配一个inode页面,分配后把所有描述符里面的FSEG_ID置为0,重复上面过程。
给新分配的Inode设置SEG_ID. 这个ID号要从表空间头信息的FSP_SEG_ID作为当前segment的seg id写入到inode entry中。同时更新FSP_SEG_ID的值为ID+1,作为下一个段的ID号。
在完成inode entry的提取后,初始化这个Inode信息。把FSEG_NOT_FULL_N_USED置为0,初始化FSEG_FREE、FSEG_NOT_FULL,FSEG_FULL。
从这个段分配出一个页面。(这块逻辑不太懂)
分配好页面后,通过缓存找到段的首页面(页面号为page+index)。就将该inode entry所在inode page的位置及页内偏移量存储到段首页,10个字节的inode信息包括:
1
2
3
4Macro bytes Desc
FSEG_HDR_SPACE 4 描述该segment的inode page所在的space id (目前的实现来看,感觉有点多余…)
FSEG_HDR_PAGE_NO 4 描述该segment的inode page的page no
FSEG_HDR_OFFSET 2 inode page内的页内偏移量至此段就分配完成了,以后如果需要在这个段中分配空间,只需要找到其首页,然后根据对应的Inode分配空间。
分配数据页函数 fsp_alloc_free_page
表空间Extent的分配函数fsp_alloc_free_extent。
对应的还有释放Segment 当我们删除索引或者表时,需要删除btree(btr_free_if_exists),先删除除了root节点外的其他部分(btr_free_but_not_root),再删除root节点(btr_free_root)
由于数据操作都需要记录redo,为了避免产生非常大的redo log,leaf segment通过反复调用函数fseg_free_step来释放其占用的数据页。
创建B+索引
innodb的文件管理方式,核心目的是为了管理好B+索引。
ibd文件中真正构建起用户数据的结构是BTREE,在你创建一个表时,已经基于显式或隐式定义的主键构建了一个btree,其叶子节点上记录了行的全部列数据(加上事务id列及回滚段指针列);
如果你在表上创建了二级索引,其叶子节点存储了键值加上聚集索引键值。所以书上贴一段创建B+索引的代码。网上找了5.6.15版本的。
这个函数就是创建一个B+树,只是概念上的,还没有真正的数据写入。
页内-页目录
1 | create table t2(id int auto_increment primary key, ch varchar(10), key(ch)); |
创建一个新的测试表 t2,有主索引 id 和 辅助索引 ch,分析 t2.ibd 文件可验证:
- 对比没有辅助索引的表,表t2多一个INDEX页,用于存储辅助索引的根结点。
- 辅助索引的INDEX页也有两个系统记录 infimum 和 supremum。而用户记录内容格式跟前面分析基本一致,内容为辅助索引 ch 列的值 ab 和 主键值1。
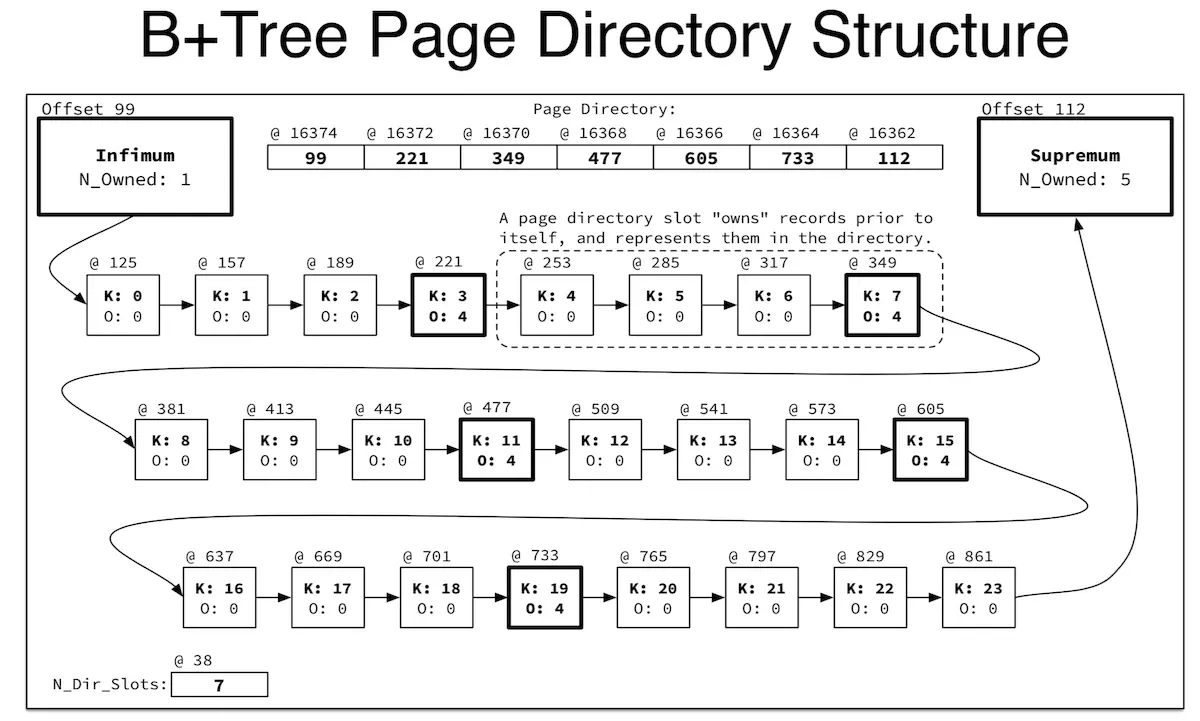
INDEX页内的记录是通过单向链表连接在一起的,遍历列表性能会比较差,而INDEX页的页目录就是为了加速记录搜索。
表 t2 中的页目录只有两项,分别是 0x63 和 0x70,即 99 和 112。
下面的ownedkey为这个页目录槽拥有的小于等于它的记录数目,显然 infimum 的ownedkey为 1,即只有它自己,没有key会比infimum小。
而 supremum 的owned是3,分别是我们插入的两条记录和它自己。
1 | slot offset type owned key |
每个页目录槽最少要包含4个记录,最多包含8个记录(包括它自己)。如果我们在表 t2 中另外插入 7 条记录,则会增加一个新的slot,即 id 为 4 的记录,如下:
1 | slot offset type owned key |
下图是页目录结构图,可以通过页目录的二分查找提高页内数据的查询性能。
参考:
http://mysql.taobao.org/monthly/2016/02/01/
《MYSQL运维内参》https://dev.mysql.com/doc/refman/5.7/en/innodb-file-space.html
链接:https://blog.csdn.net/bohu83/article/details/81086474
http://mysql.taobao.org/monthly/2016/02/01/

