摘要:mysql InnoDB 使用 B+树组织数据、查询数据、mysql InnoDB-B+树存储数据量、实际操作查看
mysql InnoDB-B+树组织数据、查询数据
在MySQL中,InnoDB页的大小默认是16k,当然也可以通过参数设置:
1 | show variables like 'innodb_page_size'; |
方式一、直接按页存储【假想】
数据表中的数据都是存储在页中的,所以一个页中能存储多少行数据呢?假设一行数据的大小是 1K,那么一个页可以存放 16 行这样的数据。
如果数据库按这样的方式存储,那么查找数据就成为一个问题。不知道要查找的数据存在哪个页中,每次查询都需要把所有的页遍历一遍,时间复杂度为 n。
方式二、用 B+ 树的方式组织数据【实际】
示例一、2层b+ tree

这个树只有2层,首先每个page都有自己的唯一编号,将来就要通过编号来找对应的page。根页做为一个第一层的索引页,里面是不存在叶子数据(行数据)的,只存放Key,同时还包含了pageNo信息,用来将来去找对应的页。
所有的记录节点都是按键值的大小顺序存放在同一层的叶子节点上,由各叶子节点指针进行连接(双向指针)。所以查询时,无论正序倒序,其实是一样的扫描速度。
每一层的最左边节点页面的最左边位置,会有一个Min记录,该记录由2部分组成,第一部分就是一个Min标记,代表这就是 最小值;第二部分是一个pageNo指针,指向下一层中最左边的记录。注意看根页的Min记录,就是这样的。而33号page的Min记录由于没有下一层了,所以没有pageNo指针。
可以看到,上一层的Key,在下一层对应的page中,也会重复存在,譬如Key=10的记录。但是,每个page,只有第一条数据会和上层有重复,其他的不会有重复。
每一个page还会有一个最大记录和最小记录,用来标记该page的边界,便于查询。
由此结构可以看到,做一次查询的耗时,每一层只需要一次内存级的二分查找,定位后就进入下一层,再一次二分查找。
譬如查询Key=11,那么可以定位到56号page,因为11小于78号page的最小值,之后找到56号page,在做一次二分查询。就能找到11。2层只需要2次IO,就能找到一条数据。3层3次,之前已经说过,3层和4层分别能存多少数据,这个查询效率其实是非常高的。
通过这样的方式,我们就知道了一颗树是怎么构成的了。
示例解说:
- B+树-组织数据
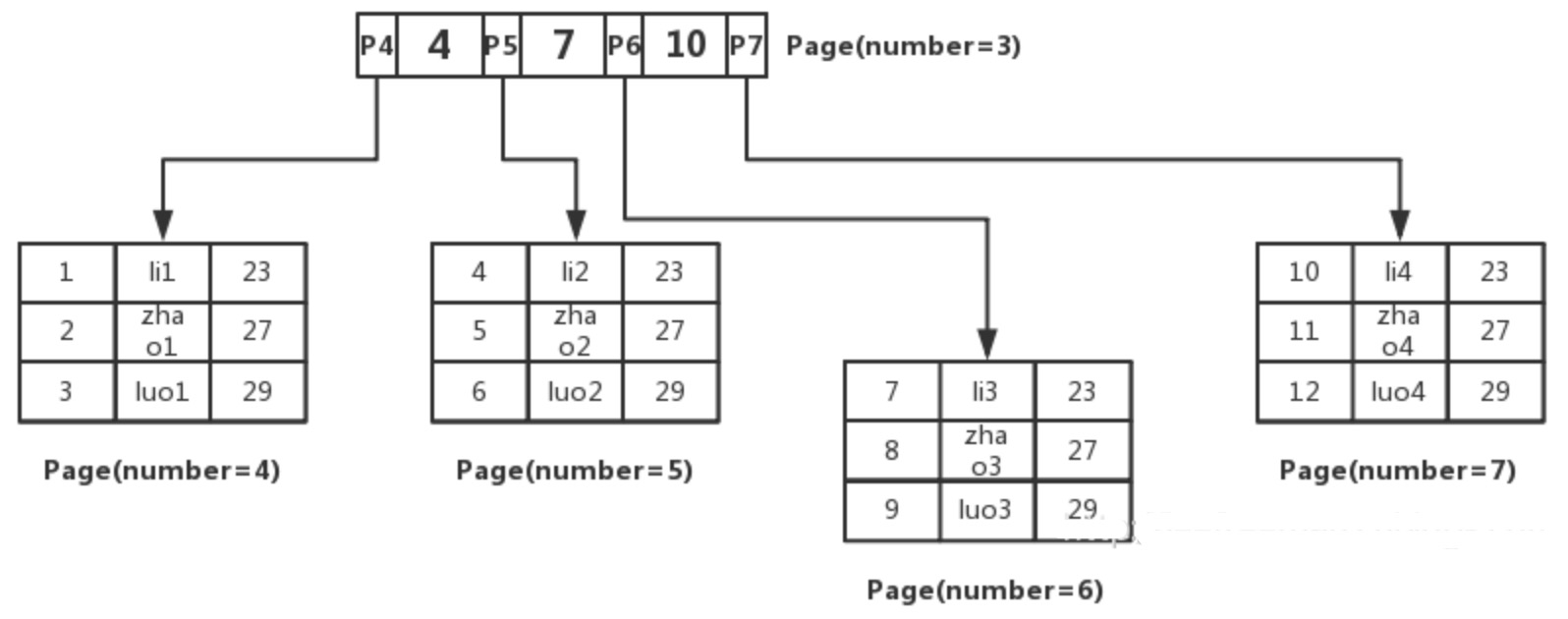
先将数据记录按主键进行排序,分别存放在不同的页中(为了便于理解这里一个页中只存放 3 条记录,实际情况可以存放很多)。
除了存放数据的页以外,还有存放键值+指针的页,如图中 page number=3 的页,该页存放键值和指向数据页的指针,这样的页由 N 个键值+指针组成。
当然它也是排好序的。这样的数据组织形式,我们称为索引组织表。
- B+树-查询数据id 是主键,我们通过这棵 B+ 树来查找,首先找到根页,怎么知道 user 表的根页在哪呢?
1
select * from user where id=5;
其实每张表的根页位置在表空间文件中是固定的,即 page number=3 的页(后续说明)。
找到根页后通过二分查找法,定位到 id=5 的数据应该在指针 P5 指向的页中,那么进一步去 page number=5 的页中查找,同样通过二分查询法即可找到 id=5 的记录:
1 | 5 zhao2 27 |
小结: InnoDB 中主键索引 B+ 树是如何组织数据、查询数据
InnoDB 存储引擎的最小存储单元是页,页可以用于存放数据也可以用于存放键值+指针,在 B+ 树中叶子节点存放数据,非叶子节点存放键值+指针。
索引组织表通过非叶子节点的二分查找法以及指针确定数据在哪个页中,进而在去数据页中查找到需要的数据。
Page内详细结构

page内的存储,共16K的空间,分为几个部分,文件管理头信息、页面头信息、页面尾信息、最小记录最大记录、用户记录、可重用空间、未使用空间、页面槽信息。
用户记录就是行数据,可重用就是曾经被分配过数据后来被删了,未使用就是没分配过的空间。
文件管理头信息
它占用38个字节,里面存储的东西主要有:
- 该页面的checkSum信息,校验文件是否被损坏的;
- 该页面在当前表空间的页面号(pageNo);
- 当前页面的上一个页面的pageNo;
- 下一个页面的pageNo;
- 当前页面最后一次被修改时,对应日志的LSN值,与后面的日志系统有关;
- 当前页面的类型;
- 只有第0号页面会存一个LSN值,用来存储当前Innodb引擎最大的被flush的LSN值,将来做checkPoint时用;
- 标记属于哪个表空间的(避免多个表空间,有相同的pageNo的页)
页面头信息
- 槽的个数;
- 未使用空间的指针;
- 存储的记录数,包括最大最小记录的管理;
- 已被删除的记录的链表的首指针;
- 已被标记删除的记录数;
- 最后被插入的记录的位置;
- 当前节点在b+ tree处于第几层,叶子就是0,往上就加1;
页面尾部:
- 这8个字节还是用来做完整性校验的。
页面重组
一个页面会频繁的插入删除,在插入过程中,都会去已经删除的可重用链表去找合适的空间,如果放得下,就会放进去,放不下,另寻空间。
时间一长,就会有空间碎片产出,譬如累计的空闲空间还有很多呢,但就是找不到能放下一条新数据的合适空间。
那么带来的问题很明显,page增加,每个page存储数据量下降,磁盘占用很大,但存的数据并不多,IO数增加,性能下降。
如果是一张表的话,如果大量数据被删,就需要及时处理回收空间,可以通过一个空的alter命令,如alter table tablename engine innodb,就可以将表的空间给回收重组了。
对于页面也一样,在数据库向某一个页面插入时,如果找不到大小合适的空间,就会做一次页面重组操作。
重组的方式是,新建一个buffer pool页面,然后将老页面的数据一条一条插入到新页面,插入完成后,将老页面空间释放掉,再修改指针位置,指向新页面。
mysql InnoDB-B+树存储数据量
数据量估算
以B+ 树高为 2为例计算
假设 B+ 树高为 2,即存在一个根节点和若干个叶子节点,那么这棵 B+ 树的存放总记录数为:根节点指针数*单个叶子节点记录行数。
上文已经说明单个叶子节点(页)中的记录数=16K/1K=16。(这里假设一行记录的数据大小为 1K,实际上现在很多互联网业务数据记录大小通常就是 1K 左右)。
那么现在需要计算出非叶子节点能存放多少指针?假设主键 ID 为 bigint 类型,长度为 8 字节,而指针大小在 InnoDB 源码中设置为 6 字节,这样一共 14 字节。
一个页中能存放多少这样的单元,其实就代表有多少指针,即 16384/14=1170。
可以算出一棵高度为 2 的 B+ 树,能存放 1170*16=18720 条这样的数据记录。
根据同样的原理可以算出一个高度为 3 的 B+ 树可以存放:1170117016=21902400 条这样的记录。
所以在 InnoDB 中 B+ 树高度一般为 1-3 层,它就能满足千万级的数据存储。
在查找数据时一次页的查找代表一次 IO,所以通过主键索引查询通常只需要 1-3 次 IO 操作即可查找到数据。
InnoDB 主键索引 B+ 树的高度
上面通过推断得出 B+ 树的高度通常是 1-3,下面我们从另外一个侧面证明这个结论。
在 InnoDB 的表空间文件中,约定 page number 为 3 的代表主键索引的根页,而在根页偏移量为 64 的地方存放了该 B+ 树的 page level。
如果 page level 为 1,树高为 2,page level 为 2,则树高为 3。即 B+ 树的高度=page level+1;
查询系统表:page level。
在实际操作之前,可以通过 InnoDB 元数据表确认主键索引根页的 page number 为 3,也可以从《InnoDB 存储引擎》这本书中得到确认:
1 | SELECT b.name, a.name, index_id, type, a.space, a.PAGE_NO |
输出
1 | blockchain_manager/member PRIMARY 22 3 6 3 |
可以看出数据库 blockchain_manager 下的 member 表、member 表、permission表主键索引根页的 page number 均为 3,而其他的二级索引 page number 为 4。
关于二级索引与主键索引的区别请参考 MySQL 相关书籍,
实际操作查看
创建测试数据
测试表
1 | CREATE TABLE `table5hang` ( |
修改表名,依次创建 table15w、table500w、table1000w
测试数据 添加
1 | delimiter // #定义标识符为双斜杠 |
插入数据,依次修改表名:table15w、table500w、table1000w 以及插入条数
根据性能 500w、1000w 数据量的需要分批插入。
查看文件结构,mysql每次建库,会在data下创建以库名为名的文件夹,内部文件是表名,如下
1 | -rw-rw---- 1 54B 1 31 11:36 db.opt |
因为主键索引 B+ 树的根页在整个表空间文件中的第 3 个页开始,所以可以算出它在文件中的偏移量:16384*3=49152(16384 为页大小)。
另外根据《InnoDB 存储引擎》中描述在根页的 64 偏移量位置前 2 个字节,保存了 page level 的值。
因此想要的 page level 的值在整个文件中的偏移量为:16384*3+64=49152+64=49216,前 2 个字节中。
1 | hexdump -s 49216 -n 10 table5hang.ibd |
小结
table5hang 表数据行数为 5 条,B+ 树高度为 1,
table15w 表数据行数为 15 万,B+ 树高度为 2,
table500w 表数据行数为 500 万,B+ 树高度为 3,
table1000w 表数据行数为 1000 万,B+ 树高度为 3。
500w、1000w 两个表树的高度都是 3。换句话说这两个表通过索引查询效率并没有太大差异,因为都只需要做 3 次 IO。
那么如果有一张表行数是一千万,那么他的 B+ 树高度依旧是 3,查询效率仍然不会相差太大。region 表只有 5 行数据,当然他的 B+ 树高度为 1。
1 | select * from table500w where id=4230000 |

